MiniCLIP is a from scratch implementation of the CLIP architecture, designed as a lightweight and deployable vision language model.
The system learns a shared embedding space for images and text, enabling zero shot classification and semantic retrieval using vector similarity.
Model Architecture
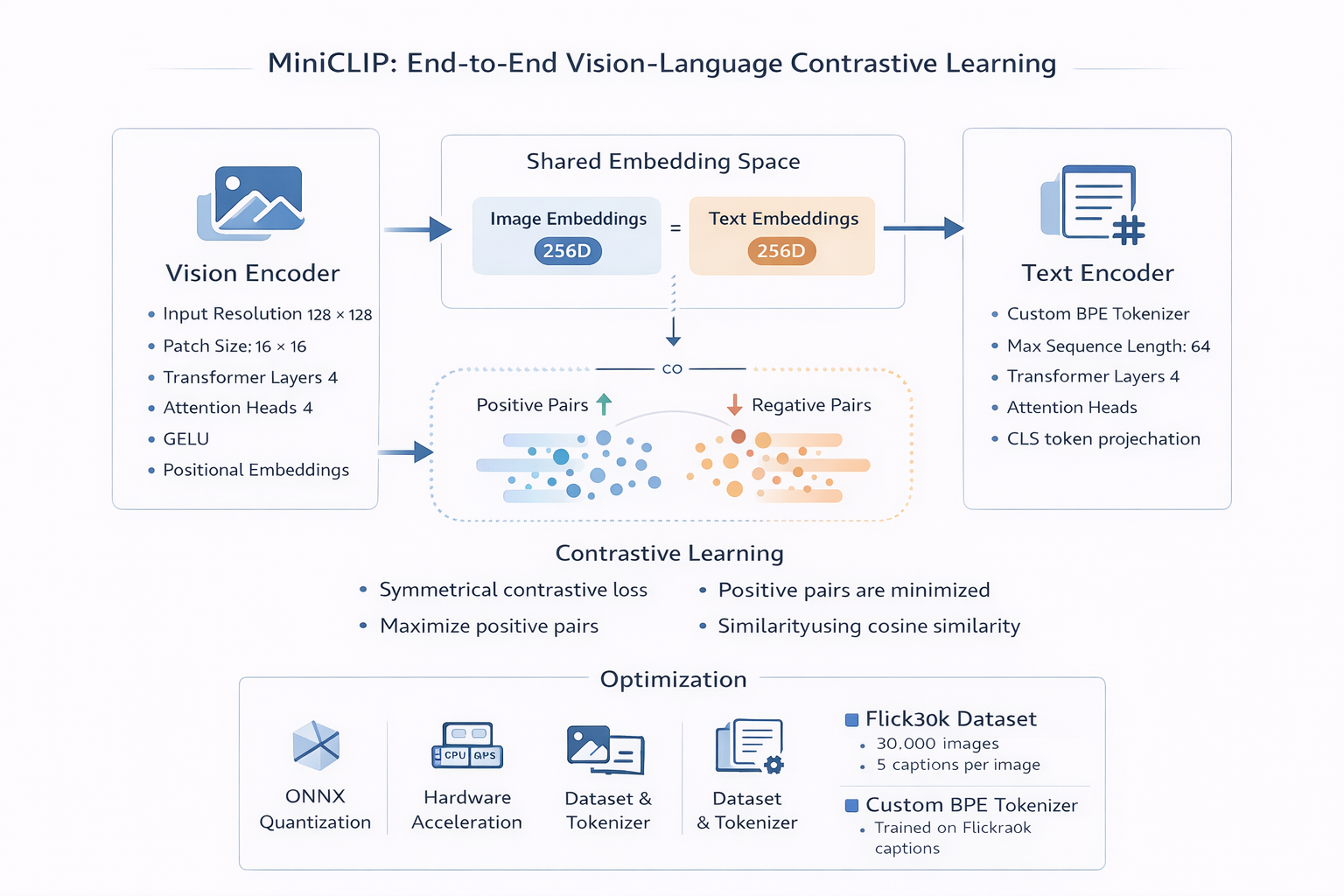
The model follows a dual encoder transformer design consisting of a Vision Transformer and a Text Transformer.
- Vision Encoder based on ViT
- Text Encoder with custom tokenizer
- Shared embedding space of 256 dimensions
- Contrastive learning objective
Training Dataset
The model was trained on the Flickr30k dataset, containing 30,000 images with multiple captions per image.
Text Processing
A custom Byte Pair Encoding tokenizer was trained on caption data using the HuggingFace Tokenizers library.
- Vocabulary optimized for multimodal alignment
- Maximum sequence length of 64 tokens
- Efficient tokenization pipeline
Model Optimization
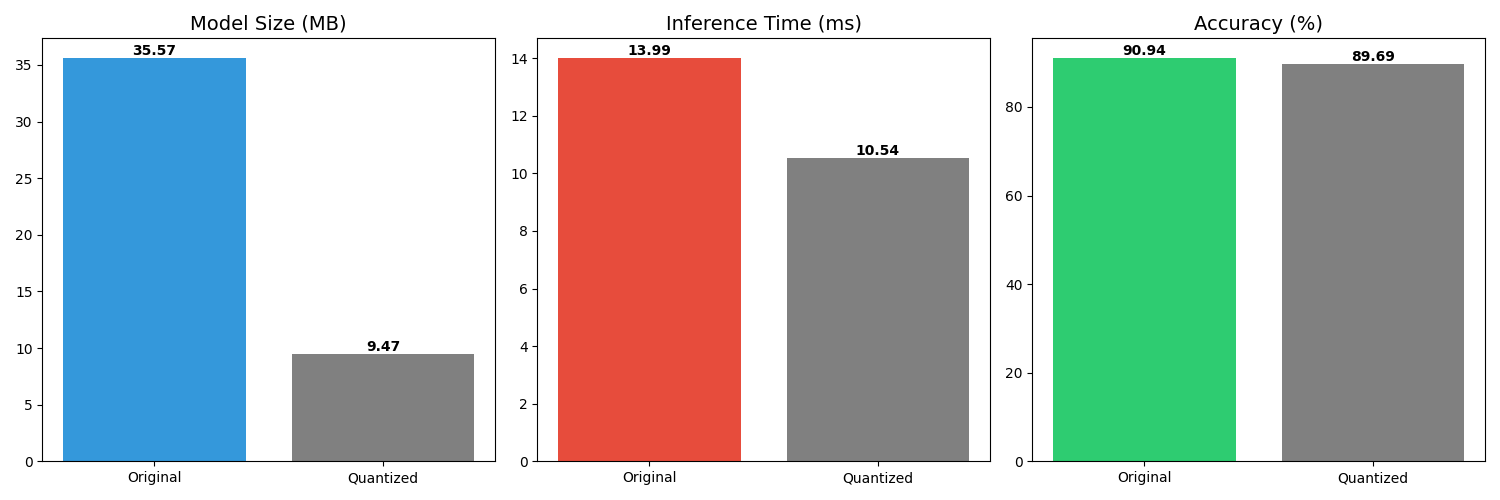
Post training optimization was performed using ONNX Runtime dynamic quantization to improve deployment efficiency.
- Float32 to Int8 conversion
- 73 percent model size reduction
- Improved inference latency
- Minimal accuracy degradation
Performance Results
- Original model size: 35.57 MB
- Quantized model size: 9.47 MB
- Top 1 accuracy after quantization: 89.69 percent
- Inference latency: 10.54 ms
Training Dynamics
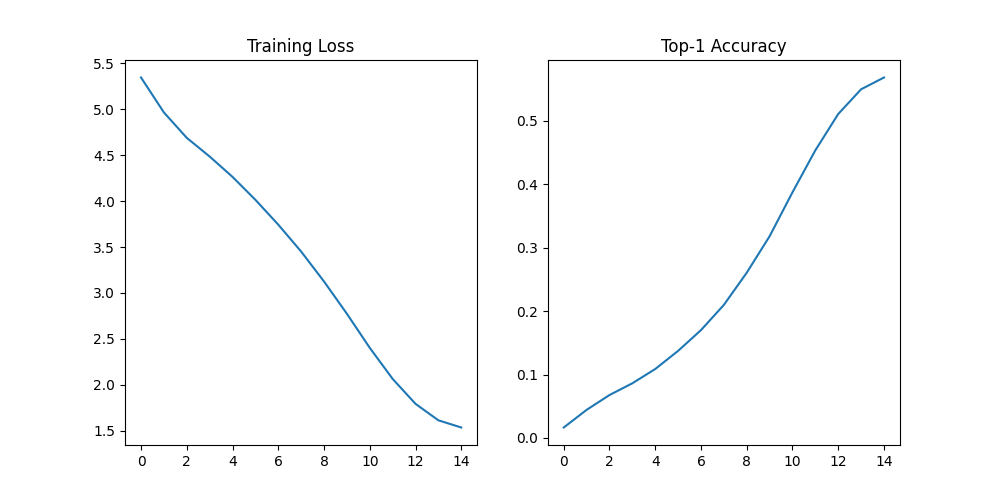
The model was trained for 30 epochs and showed rapid convergence in early stages followed by stable validation.
Zero Shot Inference Examples
The trained model supports zero shot classification and semantic image text matching.



Query Images



Technology Stack
PyTorch, Transformers, HuggingFace Tokenizers, ONNX Runtime, CUDA, MPS